Complexity in Software
instructions which a computer must follow to carry out a task. Software however can be
unbelievably complex and as, Bruce Sterling puts it, 'protean' or changeable.
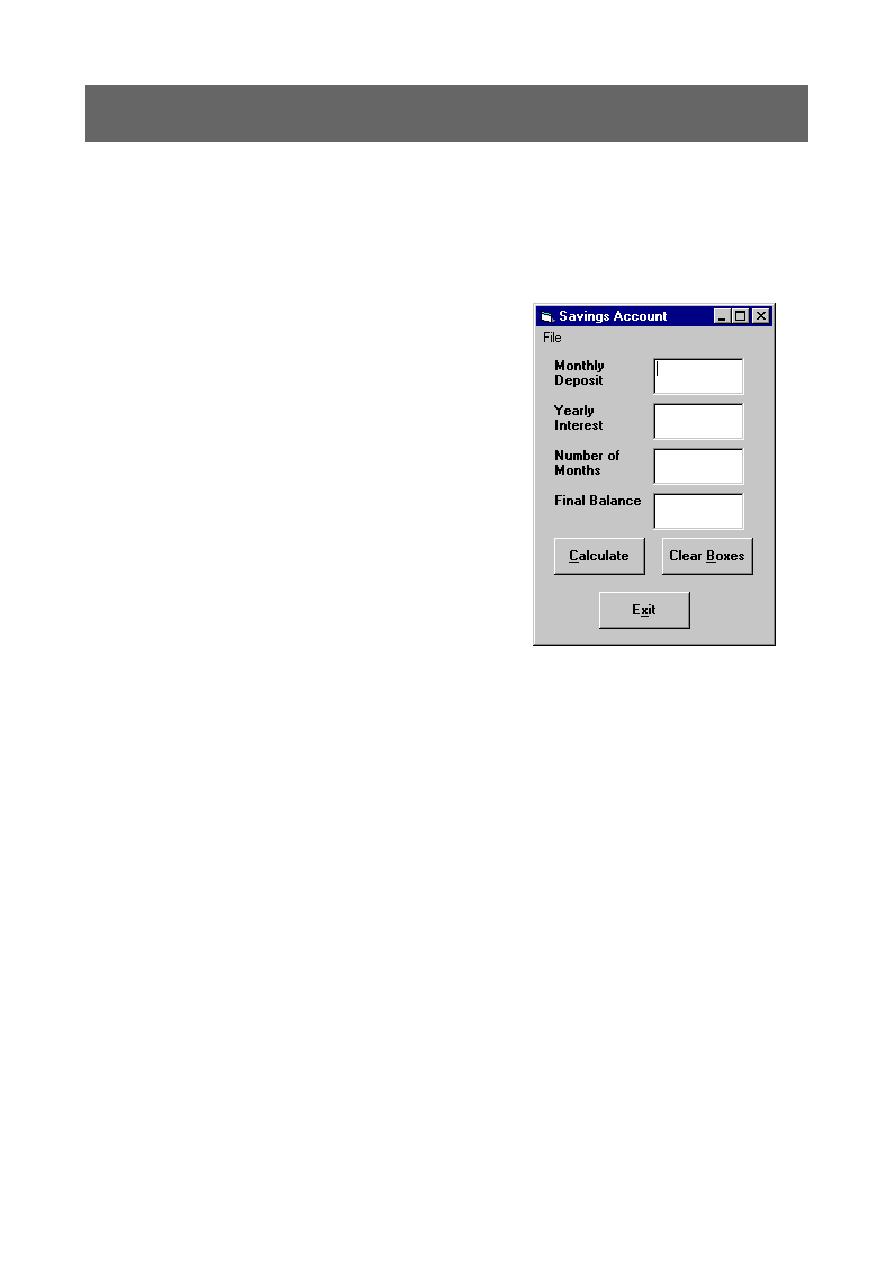
right is a simple application written in Visual Basic which
performs simple calculations for an investment. To use the
application the user simply fills in three of four of the
possible fields and clicks "Calculate". The program then
works out the fourth variable.
size and hence the number of tests required to achieve
"complete" coverage or confidence it works.
for each field there are 10
there are four input fields this means the total number of
possible combinations is 10
execute 1000 tests every second, it would take approximately 3.17x10
mean making sure we execute each branch or line of code during testing. While this gives a much
higher confidence for much less investment, it does not and will never provide a 100% confidence.
Exercising a single pass of all the lines of code is inadequate since the code will often fail only for
certain values of input or output. We need to therefore cover all possible inputs and once again
we are back to the total input space and a project schedule which spans billions of years.
by which we can group "like" values and assume that by testing one we have tested them all. For
example in a numerical input I could group all positive numbers together and all negative numbers
separately and reasonably assume that the software would treat them the same way. I would
probably extend my classes to include large numbers, small numbers, fractional numbers and so on
but at least I am vastly reducing the input set.
software, hardware and environment and can be just as flawed as the decision a programmer
makes when implementing the code. Woe betide the tester who assumes that 2