Test Case Identification
your outline and a single test may validate more than one point on one axis. For example, a single
test could simultaneously validate functionality, code structure, a UI element and error handling.
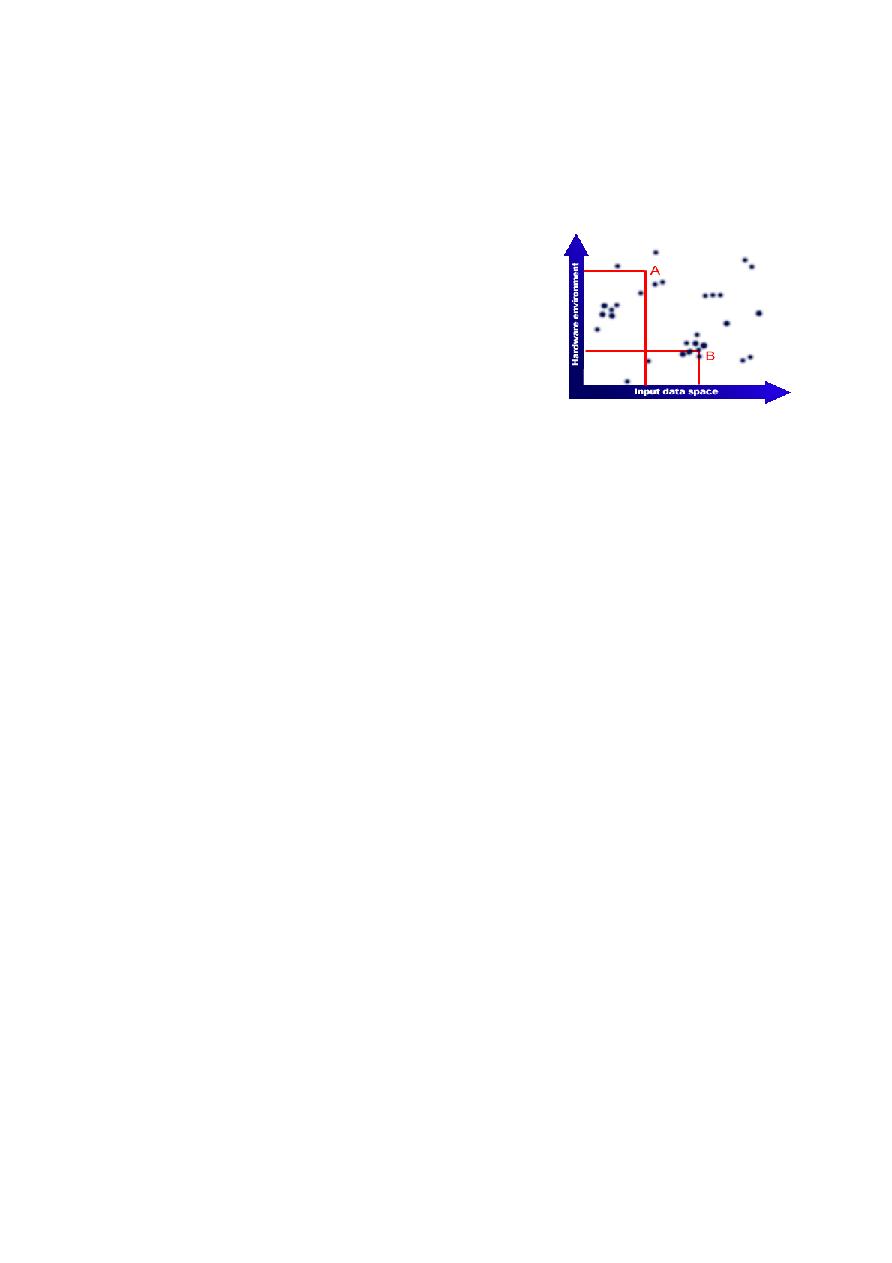
red : "A" and "B".
of the software on the two particular axes of "input data
space" and "hardware environment".
which will exercise that functionality. Note if that test will
validate a different point on a different axis and continue until
you are satisfied you have all points on all axes covered.
'what' you will test. At the end of this exercise you should have a list of test cases which represents
your near-to-perfect, almost 100% coverage of the product.
our list of test cases. We must decide which ones are more important, which ones will exercise
the areas of risk and which ones will discover the most bugs.
space" and "hardware environment". We have two test "A" and "B" and we have dark splotches,
which denote bugs in the software.
risk in the product. Perhaps this section of the code was completed in a hurry or perhaps this
section of the 'input data space' was particularly difficult to deal with.
program at that point. Test B on the other hand has identified a single bug in a cluster of similar
bugs. Focussing testing efforts around area B will be more productive since there are more more
bugs to be uncovered here. Focussing around A will probably not produce any significant results.
coverage for the most risky areas discovered. Broad coverage implies that an element in the
outline is evaluated in a elementary fashion while deep coverage implies a number of repetitive,
overlapping test cases which exercise every variation in the element under test.
to eliminate the bulk of issues. It is a tricky balancing act between trying to cover everything and
focusing your efforts on the areas that require most attention.